
Introduction
In the Web2 era, internet users gained the ability to easily "write" to the internet. While this empowered users in new ways, the explosion of content came with downsides: murky attribution, lack of metadata to describe the content, unverifiable authorship, and weak assurances around who created content and when. AI has only magnified these downsides with its ability to facilitate counterfeit and derived content at a scale never before imagined. This trajectory sets us on a collision course where inaction will have grave consequences. People tend to think Web3 gives users the right to own, however, there have been no advances that have provided users with more ownership than what currently exists in traditional “meatspace”. With strong provenance, we can move to a future in Web3 where we can use a provenance layer to enable true ownership and monetization.
Data with strong provenance, defined by permanence, unconstrained access, and precision, is key to restoring clarity and confidence in the authorship and authenticity of data. Until now, any attempts at providing strong provenance have been incomplete. Provenance layers provide the safest custody of humanity’s most valuable data.
Irys is the only provenance layer. It enables users to scale permanent data and precisely attribute its origin. By tracing and verifying where data comes from, Irys paves the way to incorporate accountability into all information.
What is provenance?
Provenance is the trail of documentation that accounts for the origin of a piece of data, which encompasses any form of attribution or labeling of the data. Provenance does not necessarily claim categorical truth or social consensus but acts as a record or attestation of some knowledge. With a credibly neutral record of history, individuals and groups can make better decisions based on verifiably accurate information.
The main attributes of provenance are timestamps, attribution, authorship, and, authenticity. The strength of these attributes is significantly enhanced when one can programmatically verify their accuracy at any point. The following details each attribute:
- Timestamps
A timestamp denotes when the data was created. It can be generated in a trusted environment by a single party or in a trust-minimized setting. The value of a timestamp is derived from its precision and accuracy; the more reliable and useful it becomes for verifying the data's history and authenticity.
- Attribution
Attribution serves to describe various aspects of the data. For example, a file might have an attribution of "Content-Type: image/png" to indicate that it is a PNG image, providing context on the nature of the data.
- Authorship
Authorship is the record of who created a piece of content. Establishing authorship is crucial for attributing its original creation. This is typically done using digital signatures to prove authorship with cryptography.
- Authenticity
Authenticity describes the ability to verify that the content and provenance attributes haven’t been altered in any way. This is typically done through merklization or content digests.
How to measure provenance?
The strength of data's provenance depends on three factors:
-
How long-lasting data is (permanence)
-
How granularly data can be attributed (precision)
-
What the limits to accessing or using data are (constraint)
Each of these factors forms a vertex of the provenance trilemma. And, for data to have strong provenance, it must be permanent, precise, and unconstrained. This can be visualized with a triad:
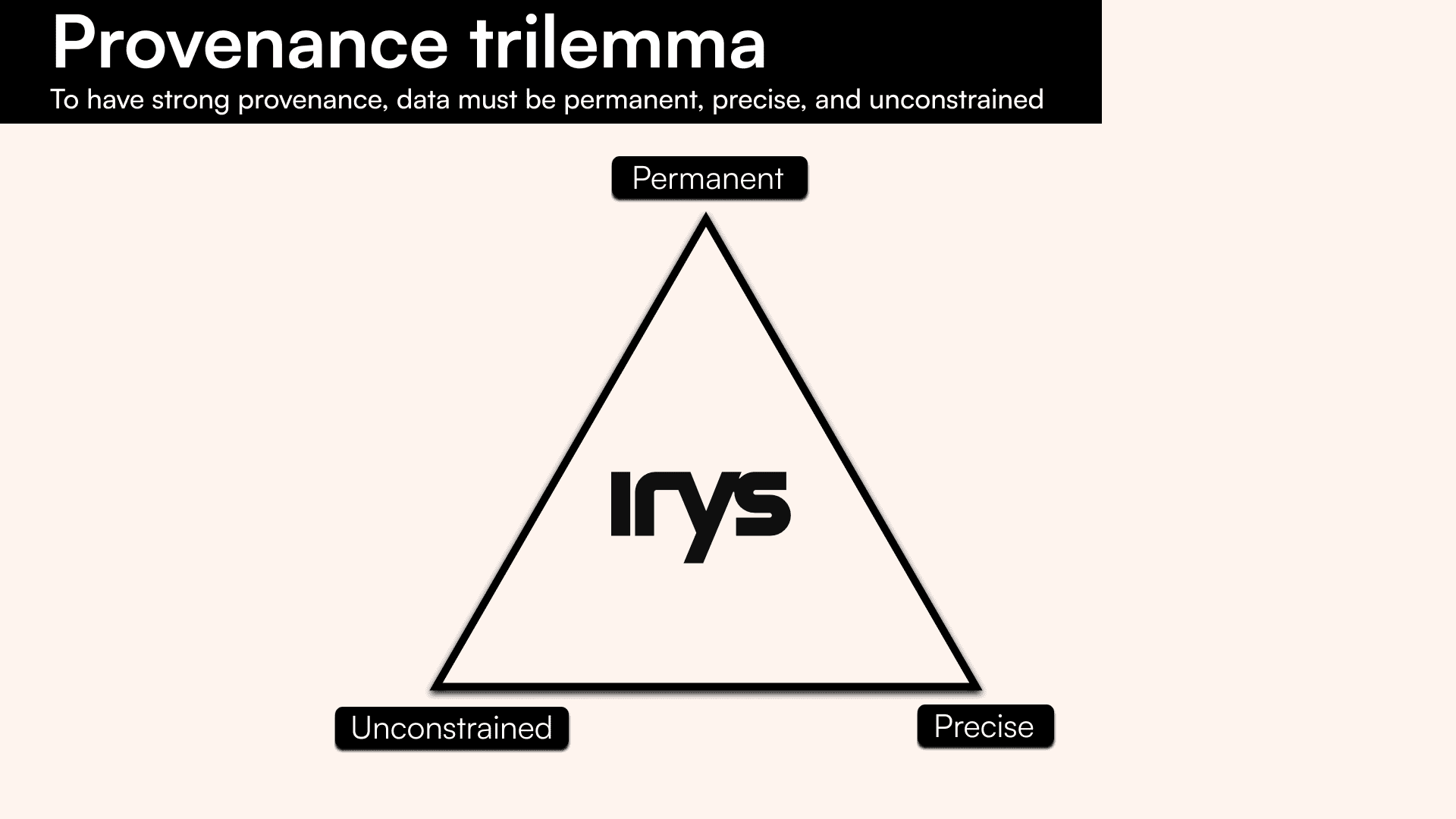
- Permanent - the ability to read the provenance log at any point in the future, giving all users the right to verify the log.
- Unconstrained - the ability for anyone to be able to write any quantity of information to a provenance log. This means providing permissionless access layers for reading and writing to the layer.
- Precise - the ability to attribute granular timestamps to data. Also described as the ability to act as a reliable witness to data.
What is a provenance layer?
A provenance layer acts as a ledger of record for digital information, tracking the origins and modifications of data. Data on a provenance layer must be permanent, precise, and unconstrained.
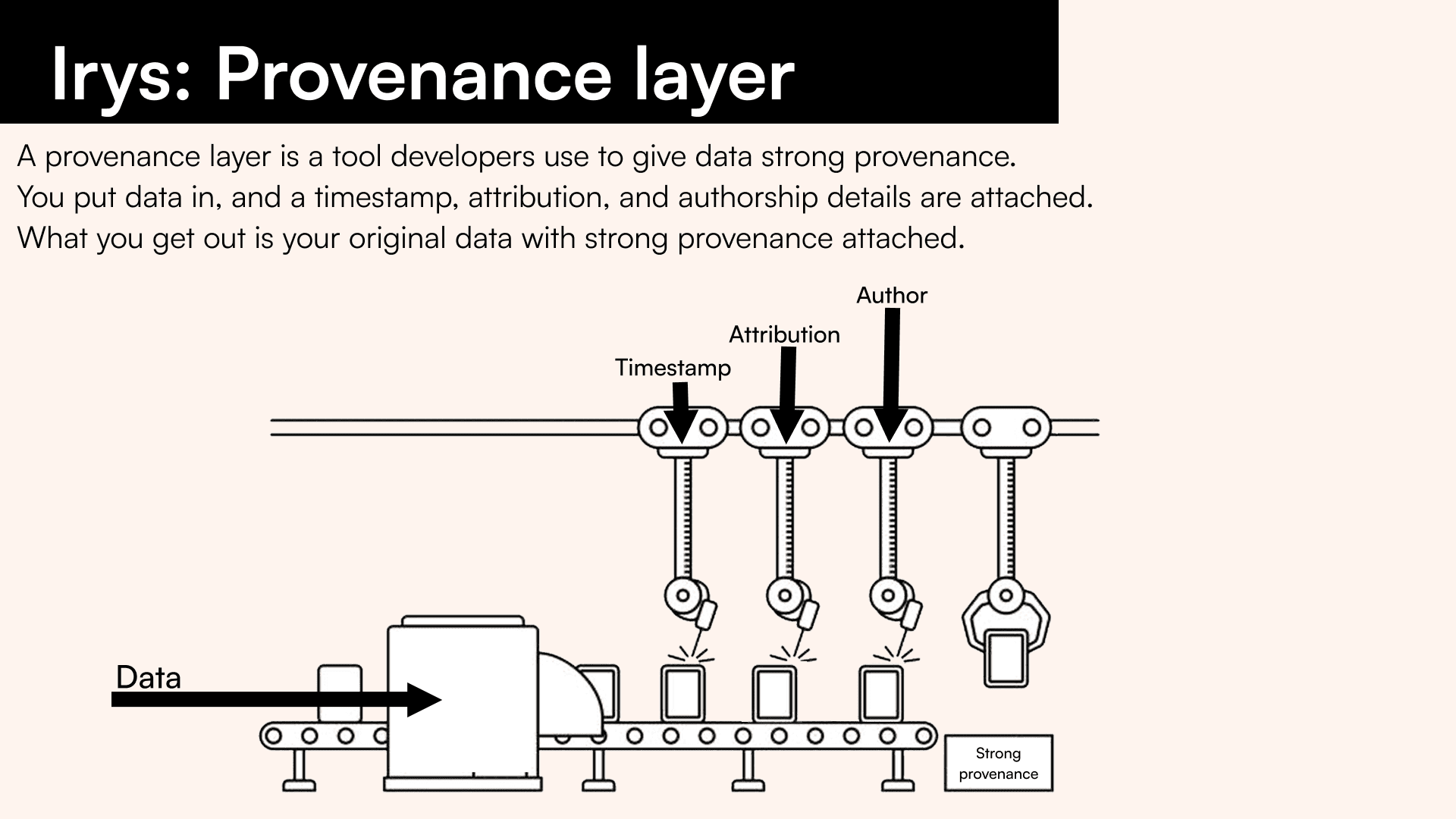
A provenance layer must have the following features:
Timestamping
Provenance layers have timestamping built in such that every piece of data is marked with the time of its creation or modification. In the context of blockchains, timestamps are applied at the block level, which means the precision of the timestamp is anchored to the block time - approximately 2 minutes for Arweave and 10 minutes for Bitcoin. Timestamp granularity is contingent on the block time, meaning the longer the block time, the less accurate it is.
Attribution
Some provenance layers provide the ability to attribute arbitrary information to data. For example, Arweave allows users to attach tags to each transaction that are a set of one-to-many key-value pairs, allowing you to add “labels” to the data.
Authorship
Provenance layers can work with different methods to track who created some content. Blockchain-based provenance layers use digital signatures as proof of authorship. This is an inherently anonymous method of authorship identity and verification.
Verifiability
A key component of a provenance layer is the ability to cheaply verify the provenance. When verifying provenance, there are several things to consider:
- Content authenticity
The process of verifying that the content has not been updated or modified in any way. When using blockchain-based provenance, content authenticity is built in, as transaction IDs are dependent on the content and attributes within the transactions. If any changes were made to the attributes or the data, the transaction ID would become invalid.
- Timestamp precision
The process of verifying that the timestamp has not been tampered with and is precise. Blockchains provide this through consensus mechanisms that provide timestamps accurate to the block time of the chain.
Identity with a provenance layer
Blockchains use digital signatures as an identity system. This allows for efficient mathematical verification of authorship and authenticity.
However, by using custom attribution, you also build upon this system with custom identity layers, such as using Worldcoin ID for proof of authorship. Provenance layers should be as agnostic as possible such that anyone can benefit from strong provenance no matter what ecosystem or technology stack you’re using. This will become more important with the proliferation of several unique identity and social graph protocols.
Proto-provenance layers
There have been previous projects that have provided degrees of provenance. We class these as “proto-provenance layers”, that fundamentally failed to be provenance layers. Proto-provenance layers are clearly displayed within the Provenance Trilemma, demonstrating their flaws:
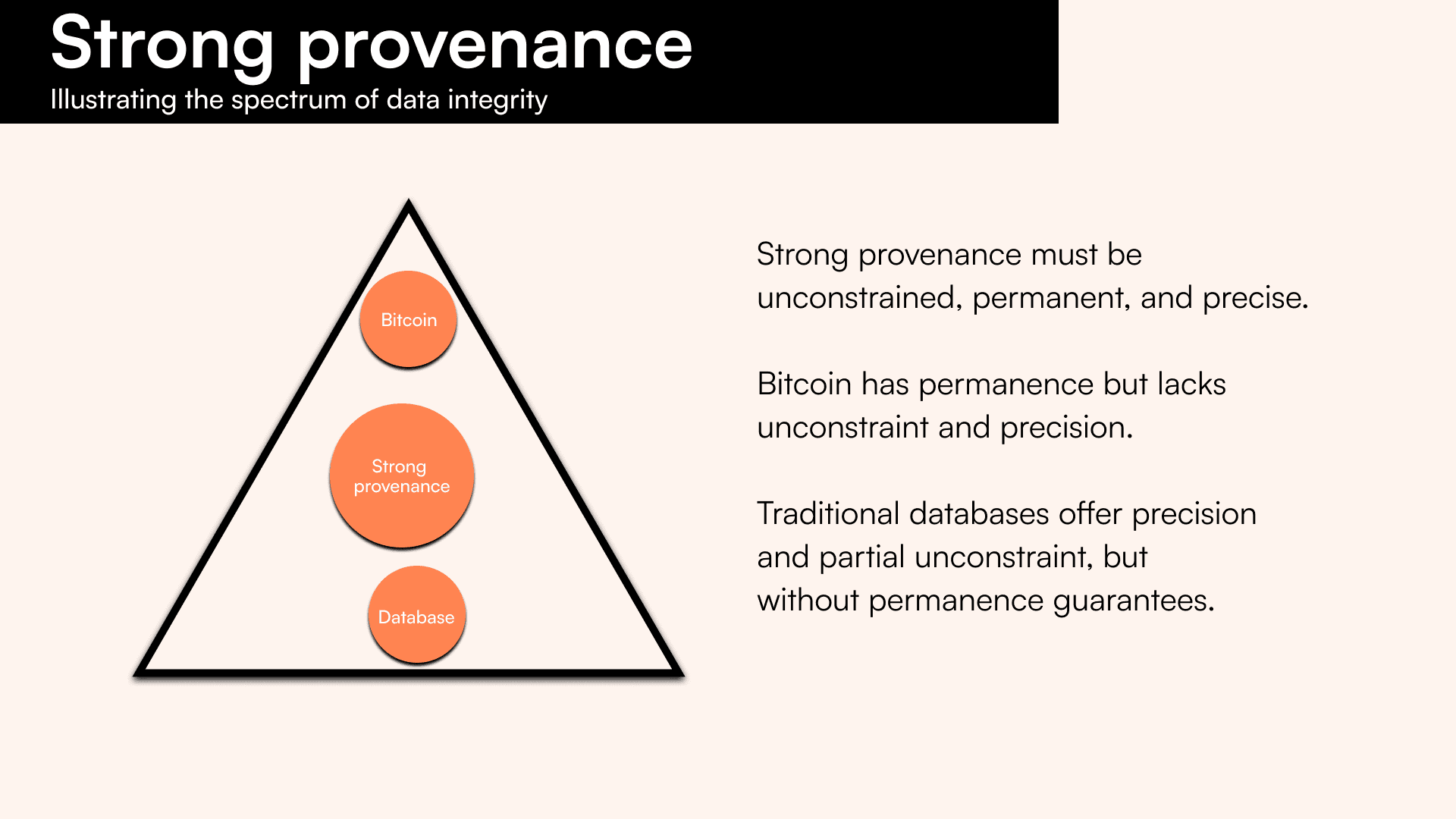
- Traditional databases
Traditional databases provide highly scalable and precise provenance, commonly storing provenance logs of transactions occurring in the database, for example, in Postgres. By the nature of their centralization, databases provide no incentives for permanently storing the data. Data stored on these databases is also mutable, allowing a trusted authority managing the database to manipulate the data. In a multiparty setup, this would provide a far lower level of security.
- Ethereum
Ethereum is a public blockchain that made the promise of providing provenance to the masses. Through Ethereum’s Proof-of-Stake (PoS) consensus, the chain provides strong guarantees on time. However, the timestamp lacks sufficient precision as it is based on block time, and blocks are mined only once every 12 seconds. Furthermore, Ethereum provides an ~8MB theoretical limit per block, creating a highly constrained provenance layer.
After applying this mental model, we can clearly see that a majority of attempts at providing provenance are either low-scale, imprecise, or impermanent.
So, where does Irys fit into all that?
Irys is the only provenance layer. It enables users to scale permanent data and precisely attribute its origin. By tracing and verifying where data comes from, Irys paves the way to incorporate accountability into all information.
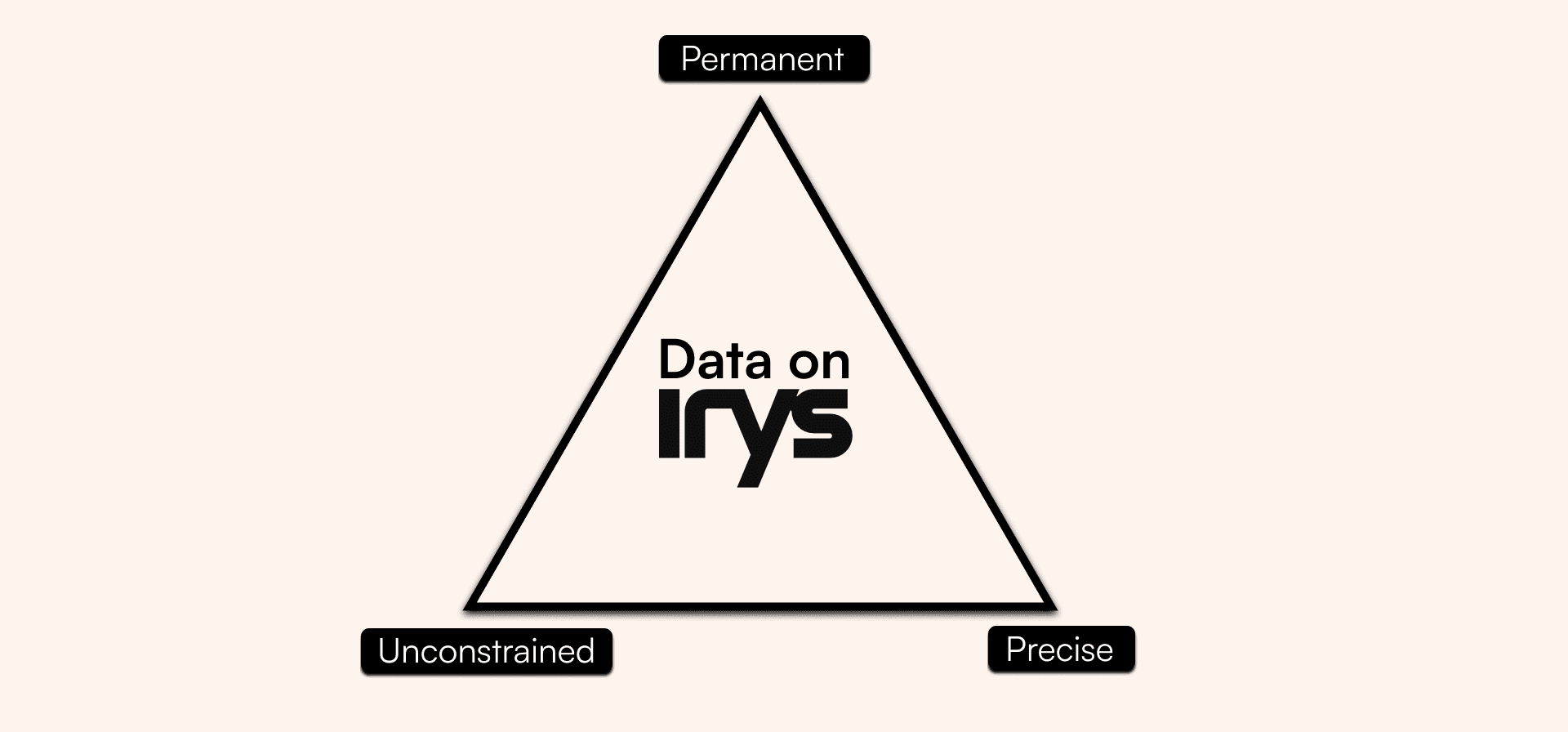
Data on Irys is permanent, precise, and unconstrained. By using Arweave, all data posted to Irys is permanently onchain and verifiable. With high throughput capacity and high-performance timestamping, Irys is able to provide access to data with strong provenance at any scale.
Irys is the only provenance layer because it is the only protocol that can satisfy all vertices of the Provenance Trilemma. Data on Irys is uploaded to Arweave, keeping it onchain permanently. This data is timestamped down to the millisecond, making it extremely precise. Finally, Irys' volumetric scaling makes it so there are no limits to its scalability. Users have the unrestricted ability to read from and write to Irys, making data on the network completely unconstrained.
In short, Irys provides strong provenance to resolve the provenance trilemma.
Future of provenance
Provenance layers ultimately enable chains of custody to track key attributes related to the data. Once we have a robust provenance layer, we can start to build ownership mechanisms that provide users rights on onchain data. Forward Research recently released the Universal Data License (UDL), which provides a framework for attaching licenses to data posted to Arweave. This means creators are able to enforce their rights onchain.
Over time licensing as a primitive will move onchain with development in zero-knowledge (zk) cryptography This will provide easy ways for users to verify how different pieces of data are linked, which is enabled through the use of zero-knowledge (zk) transformations, a primitive used to prove that certain changes to data were made, e.g., reducing the size of an image. Dan Boneh recently released an article discussing the importance zk transformations will have on the way we build future protocols and applications. With this new primitive, having a provenance layer as a scalable ledger for the proofs will become increasingly crucial. Once anyone can generate succinct zk proofs of changes to data, you can start to build decentralized financial rails for data-focused protocols. For example, Lens Protocol, a Web3 social graph, could support zk proofs on content to prove that remixed content came from the source content and distribute revenue based on smart contract rules.
In conclusion, the necessity of strong provenance, both now and in the future, should be self-evident. At Irys, we’ve built the tools needed to create a future where content attribution, authorship verification, and authenticity are trustlessly verifiable. By incorporating these components, Irys enables users to programmatically verify the authenticity surrounding data's history, fostering trust in historical records and knowledge without the need for intermediaries.
Irys is paving the way for a new era of applications where information can be trustlessly verified, heralding a future where confidence is derived from incontrovertible proof rather than mere assertions.


