
Introduction
In my previous piece, "What is a provenance layer?" I introduced provenance and provenance layers. I discussed the Provenance Trilemma, which describes the tradeoffs of proto-provenance layers. Until now, all proto-provenance layers have failed to provide robust provenance solutions, bringing either ephemeral provenance or solutions with low precision or scale.
Strong provenance, which includes permanence, precision, and unconstrained access, is the key to restoring clarity and confidence in the authorship and authenticity of data. Until now, any attempts at providing provenance have failed.
Irys is the only provenance layer. It enables users to scale permanent data and precisely attribute its origin. By tracing and verifying where data comes from, Irys paves the way to incorporate accountability into all information.
What is the provenance trilemma?
The Provenance Trilemma is a representation of the tradeoffs proto-provenance layers have had to make in the past. It describes the tradeoffs between data being permanent, precise, and unconstrained.
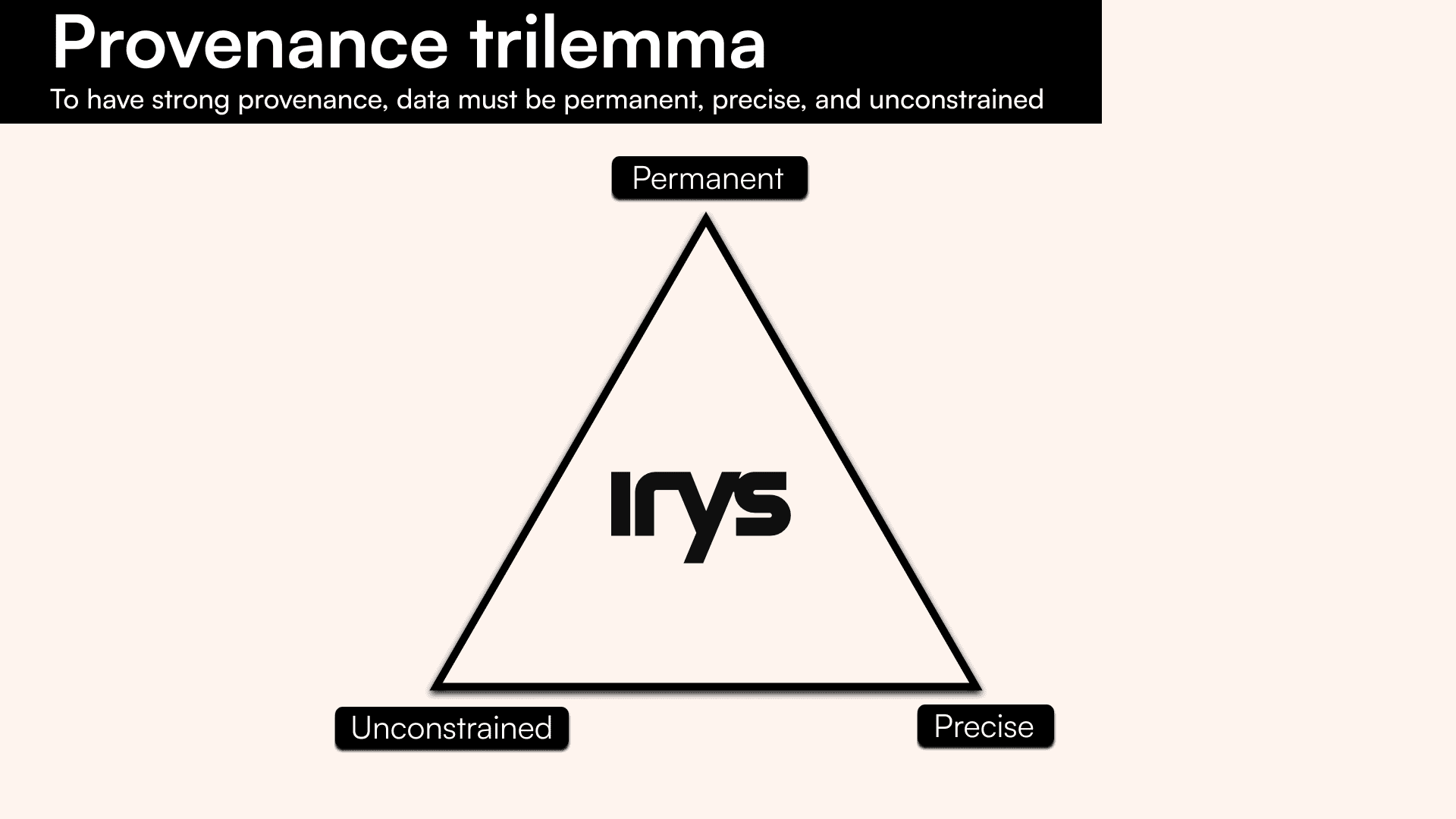
Data with strong provenance is permanent
Permanence guarantees that the data can be retrieved at any point in the future. Permanent data is fault-tolerant, tamperproof, and paid-for:
Fault-tolerant
This means that the data is stored so that it can survive unexpected events, including data corruption and loss. This typically comes from replicating the data redundantly across geographies and hosts.
Tamperproof
The stored data is immutable, so it can’t be maliciously changed. This is typically done through merklization or content digests, two techniques that use deterministic hashes to ensure data never changes.
Paid-for
This means that the cost of storing the data permanently is covered up-front, and there is a mechanism for paying miners on an acceptable cadence. This provides strong incentives for storing the data forever.
Data with strong provenance is precise
Precision describes both the granularity of the timestamp and metadata attributed to the data. Precision is essential when building high-scale infrastructure or protocols which need stronger guarantees on sequencing and attribution (e.g., Lens Protocol). When considering the precision of provenance, there are three factors involved:
Timestamp granularity
The granularity of the timestamp determines both the scalability and accuracy of applications you can build, allowing more control over how data is attributed. The precision of a blockchain’s timestamp is tied to its block time. If the block time is 10 minutes - like with Bitcoin - then the timestamps generated by the chain are accurate to +/-10 minutes.
Custom attribution
A key component to precision is providing the ability for the signer of the data to attach extra information to the data. This allows for full customizability of the provenance tied to data. If there is no de facto way to attribute data, then the provenance is weak.
Verification
This describes the ability for users to verify the provenance of data, including all of its core attributes: timestamp, authorship, attributes, and authenticity. Blockchains tend to use light clients as a method for verifying chain state. Similar approaches can be applied to verifying provenance.
Data with strong provenance is unconstrained
Constraints restrict the number of users participating in reading, writing, or verifying the provenance of data. Provenance layers provide an entirely unconstrained form of provenance, allowing anyone to read, write or verify provenance without any limits on throughput.
Scaling reading and writing
This describes the ability to scale access to provenance for reading and writing. This means there should not be any limits on the volume of data or transactions a user can read or write at any time.
Verification at scale
A key component of provenance is the ability to verify that it hasn’t been maliciously changed. The easier and cheaper it is to verify the state of a decentralized system, the more decentralized it is.
Permissionless access
This describes the ability for anyone to have access to the provenance. This means anyone can read, write or verify the layer without any restrictive authorization process.
Irys is the only solution to the provenance trilemma
Proto-provenance layers, such as Ethereum and Bitcoin, have fundamentally failed in providing provenance as they cannot scale nor provide any guarantee of permanence. In order to satisfy the Provenance Trilemma and be a provenance layer, the data provided must be permanent, precise, and unconstrained; Irys is able to serve humanity’s demand for provenance.
Data on Irys is permanent, precise, and unconstrained. With high throughput capacity and high-performance timestamping, Irys provides strong provenance at any scale.
Irys is the only provenance layer because it is the only protocol that can satisfy all vertices of the Provenance Trilemma. Data on Irys is uploaded to Arweave, keeping it onchain permanently.
Before seeding to Arweave, Irys generates a millisecond-granular timestamp which can be stored alongside the data as proof of when the data was created. Irys does this by generating cryptographic receipts, which are used as time proofs. Currently, users have the choice to hold the receipt locally or store it permanently alongside the data.
Finally, Irys’s volumetric scaling makes it so there are no limits to its scalability, making data on Irys completely unconstrained. Volumetric scale means users have the unrestricted ability to read and write to Irys, with the ability to verify permissionlessly.
In short, Irys gives data strong provenance, resolving the Provenance Trilemma.
Conclusion
Until now, we haven’t had a solution to the Provenance Trilemma, meaning blockchain-based technology never reached its full potential outside financial use cases. With Irys, developers can now build infrastructure with provenance at scale. Irys expands the design space for the average developer, allowing anything from a trustless supply chain to an entire creator economy.
Irys is the only provenance layer.


